Chapter 7. Models of Network Selection: Basics
The distinctive aspect of social network analysis is its focus on the relations between actors, rather than the attributes of actors, as the basic building-block of society. What is probably most distinctive about the application of statistical modeling in SNA is its tool kit for thinking about patterns of relations (or social structures, or networks) as a dependent variable. In this chapter, we’ll take a look at how SNA approaches explaining and predicting networks.
The formal mathematical definition of a network is very simply a set of nodes and the set of edges (if directed) or arcs (if non-directed) among them. The models we are considering have a fixed set of nodes. So, what distinguishes one network from another is the presence or absence of arcs/edges, or their strengths. To describe a network (or the difference between two), we would make lists. These lists would have the identities of all possible pairs of nodes, along with a description of the relation between the nodes. That is, networks can be described, formally, as lists of the “attributes” of all possible dyads.
Less formally, statistical models for explaining or predicting networks operate by using independent variables to predict the state of the relation in each possible dyad among a set of actors. If we had a group of three people (A, B, C), and the symmetric tie of “is a friend of,” we would seek to build a model to explain or predict whether A and B were friends, whether A and C were friends, and whether B and C were friends. In this simple case, there are four possible “kinds” of networks or social structures (no ties, one tie, two ties, three ties). The unit of analysis when we are taking the network as our dependent variable is the dyad.
Building theories about why social structures or networks vary then, is building theories about how ties are created and ties are dissolved with different probabilities that are dependent on explanatory variables. That is, SNA theories of social structure are “generative” and talk about processes that create or break social ties. The corresponding statistical models used to describe networks or test hypotheses about them involve using independent variables to predict, for each dyad, the state of the relation between them.
The unit of observation is the dyadic tie. The “N” in models predicting networks is the number of possible dyads or unique pairs of actors. For directed networks (i.e. where AB does not necessarily imply BA), the number of dyads is K*K-1, where K is the number of actors. For non-directed networks, it is half this number (because AB implies BA).
The dependent variable (the tie between A and B) can be measured at any level. To date, most statistical models for networks use simple binary measures (the tie AB is either present = 1, or absent = 0). In principle, however, ordinal, counts, multinomial, or interval measures of ties could be used.
The independent variables are used to explain variation across dyads in the presence/absence (or form, or strength) of ties. Following Lusher and Robbins (2013, p. 24), it is useful to think of three broad classes of independent variables in models predicting networks: variables that reflect network self-organization processes, variables that measure effects of actor attributes, and variables that measure the effects of exogenous context.
Network self-organization processes suggest that the likelihood of a particular new tie forming (or an existing one disappearing) depends upon the current state of the network and the location of the tie in that network. This might sound a bit abstract, and some examples of self-organizing processes will help.
Consider three actors (A, B, C), with no ties. If a tie is added, which one will it be? It could be AB, BA, AC, CA, BC, or CB (if the ties are directed). Knowing nothing else about A, B, and C, we would probably guess that any one of the six possibilities is equally likely.
Suppose that the tie AB did form (here, A is the source node, the one directing the tie, and B is the destination node). What happens next? There are five possibilities (BA, AC, CA, BC, CB). One theory (randomness) would predict that each of these five is equally likely. But, we might have some alternative, substantive theories.
The theory of “activity” suggests that actors may differ in their capacity/motivation to direct ties at others. If this theory is true, then the tie AC might be more likely than any of the others (because an actor who has already formed one tie is more likely to form another; i.e. A’s behavior can be categorized as “active” or “outgoing”). Or, we might suppose that “popularity” is operating. If actors vary in popularity, then actor B, who was selected on the first round, would be more likely to be selected by actor C forming CB on the second round. Theories of social processes suggest that some actors are more capable/likely to make ties than others (they are more active or sociable). Theories also sometimes suggest that “the rich get richer” or that actors who have ties already are more likely to get additional ones.
In many social situations, there are norms of reciprocity operating. If we theorize that norms of reciprocity are dominant in the three node network, we might then hypothesize that in the network with a single tie, AB, the next tie to form would most likely to be BA.
Alternatively, a theory of brokering might predict that in the three node network with a single tie AB, the next tie to emerge would most likely be BC, forming a line in which B is a broker between A and C.
What if two ties exist, what is likely to happen next? Popularity, activity, and reciprocity might all continue to operate. But, new kinds of structures can now emerge. If we have AB and BC, we might see CA form – creating a “closed circuit.” If instead, the directed tie AC emerged, forming a triad, we’d find a more complex hierarchy.
There are a number of different ways of thinking about these sorts of self-organizing processes. Most theorists suggest that activity/popularity (or the shape of the in and out-degree distributions), reciprocity, closure, and brokerage are often important processes. Some analysts think that most of the important variation in network structures can be described by looking at configurations of three actors (see our discussion of the triad census, below). Other analysts believe that some additional more complex structures (e.g. cliques of 4 or more actors, multiple 2-paths, multiple triangles, etc.) are formed by additional social processes.
In any case, the basic notion of self-organizing network processes is that the existing structure of a network affects what happens next. In other words, the likelihood of a tie forming or dissolving depends on how it is embedded in the network structure itself. The processes being described are general ones that operate independently of the attributes of the actors.
Actor attribute processes of generating networks are more familiar. We might suppose that men are less likely than women to form ties due to gender socialization and expectations. We might suppose that actors who are supervisors are more likely to form out-ties, and that actors who are workers are more likely to form in-ties. We might also think that ties between supervisors or between workers are more likely to be reciprocated, while ties between workers and supervisors are less likely to be reciprocated. That is, we might suppose that the likelihood of a given tie forming depends on the attributes of the potential sender alone, the potential receiver alone, or the attributes of both (homophily, anti-homophily, hierarchy, etc.).
The effects of actors’ attributes bias the basic processes of tie formation. That is, they “interact” with the self-organizing tendencies of networks. To say that women are likely to have more ties than men is to suggest that gender affects or biases processes that create density and degree distributions. To say that two nodes at the same level in a hierarchy (workers or supervisors) are more likely to form a reciprocal tie suggests that homophily of rank increases the probability of a tie being reciprocated. Triads and larger structures may be more likely to form among actors who share the same trait (ethnicity, gender, age, etc.).
Exogenous context, or other dyadic relations among actors may also affect the likelihood of forming ties, reciprocating ties, forming closed structures, and the like.
In our classroom example (see Chapter 2, or the “Classroom Data Codebook” found here, for details), we assigned students to work-groups – i.e. we externally imposed a structure of affiliation. We might suppose that being affiliated with the same workgroup would set processes in motion that would create a greater density of ties (and perhaps reciprocity and closure) among group members. In an organizational setting, we might suppose that the formal “chain-of-command” network would bias the network of informal “friendship” or “advice seeking” ties. Two actors who are closer together in geographical or temporal space might be more likely to form ties than actors who are further apart.
In all of these examples, one dyadic relation is shaping or “training” the pattern of ties in another. The ties of affiliation of students with workgroups would normally be represented as a student-by-student matrix, with a “1” indicating that the dyad were in the same work group, and a “0” if not. Similarly, the chain-of-command in an organization can be represented as a network of who gives orders to whom. The geographical or temporal distances among actors are represented as a dyadic matrix of distance or closeness.
To quickly summarize:
Analyzing networks (or relations or structures) as dependent variables is done by treating the state of the relation of each dyad as the dependent variable. “N” is the number of pairs of actors, or dyads.
Conventional descriptive/predictive modeling approaches are then used to account for variation across dyads in the nature of their relation. By far the most common approach is logistic regression predicting the presence or absence of each dyadic relation.
While any set of independent variables can be introduced to explain or predict dyadic relations, SNA approaches suggest that self-generating structural processes, attributes of the actors, and the effects of structural contexts (other networks) are important classes of explanatory variables.
The most important and widely used general approach to predicting or explaining networks as outcomes is the “Exponential Random Graph” (ERG) or P-star tradition. There are many local variations, adaptations, extensions, innovations, and advanced applications tuned to particular research areas in this general tradition. In this chapter, we’ll first look at a simple tool in UCINET for building a basic ERG model. Then, in the next chapter, we’ll briefly look at the basics of PNet, which allows a much greater range of models (but is more difficult to use).
At present, ERG modeling approaches for non-binary networks have not been developed to any useful level. So, analyzing networks that measure relations as counts, probabilities, ranks, types, or strengths are not readily available. To a limited degree, it is possible to use multi-level models in the generalized linear modeling tradition for outcomes of these types. We’ll look at some ideas along these lines in the next chapter as well.
The generative theories of social networks are largely “bottom-up” theories. Networks are seen as emerging from the agency of actors operating in local neighborhoods, which make and break ties. In looking at larger social structures then, it is often interesting to examine the variety of local structures that comprise them. Suppose that the social network among the students in one class has many more ties than another, but that ties in the second class are much more likely to be reciprocated if they exist. These two classes have quite different potentials for how they may behave at the macro level. At the micro level, most students in the first classroom are likely to have at least some ties to other students, but students are likely to have “open” ego-networks. In the second classroom, students have fewer alters per social tie, and form tighter and more closed local social worlds.
The exponential random graph approach to modeling networks predicts the presence or absence of a tie (or the tie strength) between each pair of actors as a function of a small number of basic network parameters, and how actor (and dyadic) attributes affect these parameters. For example, an ERG model might propose that women have more ties than men, but that the ties of men are more likely to be reciprocated.
Before doing ERG modeling, it is a good idea to take a look at the prevalence of various local structures in the network. One tool for this is the “triad census,” which counts up the numbers of triads in a graph that have all logically possible structures.
For symmetric (bonded, non-directed) graphs, the story of the triad census is pretty simple. Focusing on any given triad, it can have one of four possible structures: no ties, one tie, two ties, or all three ties. Obviously, the more triads there are that have multiple ties, the greater the overall density. But the ratio of the number of triads that have two ties to those that have three ties tells us something about the likelihood of transitivity for a given density, for example.
For asymmetric (directed) graphs, the story is more complicated. The number of ties among a given three actor set can vary from 0 to 6. But, more than that, there is more than one way for a directed triad to have, for example, two ties. In fact, there are 16 possible configurations of the ties among three actors. The triad census for directed data, then, reports on the prevalence of 16 different configurations.
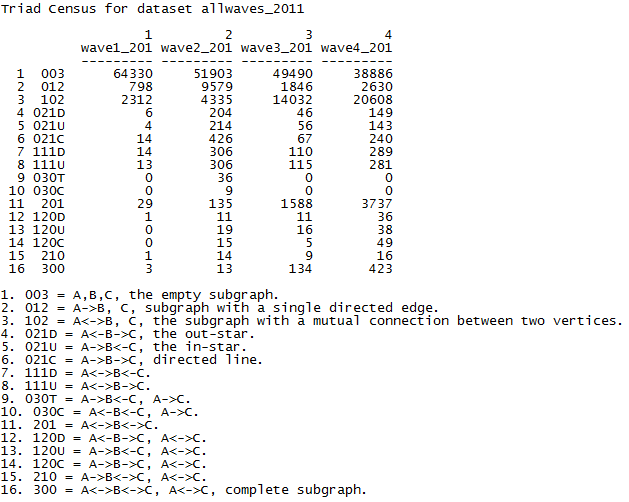
In figure 7.1, we see the results of running UCINET’s Network>Triad Census on all four of the waves of the student acquaintanceship data in its asymmetric, or directed form using the file “allwaves_2011” (this file was created in Chapter 2).
Figure 7.1. UCINET’s Triad Census for Student Acquaintanceship, Asymmetric
The top panel reports the numbers of directed triads across the four waves that had each of the 16 possible configurations. The lower panel provides a key to the configuration names. A few observations illustrate how the triad census can provide insights. The number of “empty” triads (003) declined from 64,330 to 38,886 over the term (and, most rapidly during the time before the first mid-term, which was between wave 1 and wave 2). 021U and 021D (out-star and in-star) configurations changed in step, reflecting the ideas that activity processes and processes of preferential attachment are equally likely to occur in this network. A relatively large amount of “strong cliques” (triads with all 6 ties present, or three reciprocated relationships) emerged, compared to the numbers of configurations close to these “complete subgraphs”.
Observations like these should focus ones attention on two things: the likelihood of different mixes of configurations changes as the overall density of the graph increases; and, one is led to wonder what kinds of actors (i.e. actors with what attributes) are more or less likely to be involved in which kinds of local structures.
Let’s simplify the picture now, and take a look at the triad census for the four waves where the data have been symmetrized (Transform>Symmetrize) using the “maximum” method (if either A ->B, or B->A, then A<->B.
Figure 7.2. UCINET’s Triad Census for Student Acquaintanceship, Symmetric (Maximum Method)
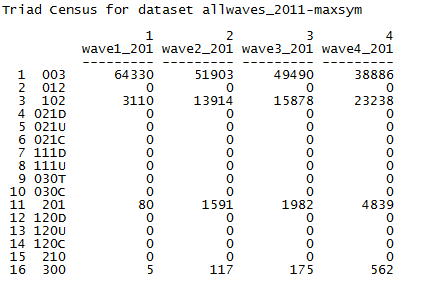
We see that the relative numbers of triads with zero, one, two, and three ties change rather remarkably as the total density of the graph increases. Students are increasingly likely to become embedded in local structures that are more closed and dense. In looking at a triad census like the one in figure 7.2, it makes sense to ask about the ratio of empty triads to triads that are not empty; then to ask about the ratio of triads with two or more ties to those with one tie; then to ask about the ratio of triads with all three ties to those with two. That is, the triad census reflects an inherent underlying hierarchy. You cannot have a structure with three ties until you have a structure with two, etc.
Exponential random graph models predict the presence or absence (or the strength) of ties between pairs of actors. In doing so, they explicitly recognize that the likelihood of a given tie is affected by the overall density of the graph, and the overall tendencies in the graph for local ties to be reciprocated, to form local closed structures, and for the overall degree distribution of the graph to be unequal (preferential attachment). Going beyond these tendencies, ERG models ask what kinds of actors and dyads are more or less likely to have ties, within the constraints imposed by the overall structural biases of the graph.
The earliest stochastic model of graph structure to gain wide-spread use was proposed by Holland and Leinhardt in 1981. The P1 model continues to be a very useful tool for describing the structure of a graph. It also is a good way of understanding some of the basic ideas underlying the exponential random graph models that we will examine in the next chapter.
Suppose that we had a set of k nodes, with no ties among them. Let’s select two of the nodes at random, and add a tie. Now, let’s select two nodes again, including the two nodes that are already connected, and add a tie between these two (unless, by chance, we happened to select the same two nodes that already had a tie). We can continue this process of random graph construction until all pairs are connected (i.e., the density is 1).
As the density of our random graph increases, structure emerges. When we add the first tie, we have created a graph with one dyad and k - 2 isolates. This is the only possible emergent structure, so that we know it has a probability of 1.0 in a random graph with only one tie. Another thing to note is that the “degree distribution” has changed as we added a tie. Rather than all nodes having a degree of zero, we now have two nodes with a degree of 1, while all the remaining nodes have a degree of 0.
When we add the second tie, there are two possible emergent structures. Either we form a structure with two dyads and k - 4 isolates (the most likely outcome), or we create a structure with one 3-node “line” and k - 3 isolates. With two ties, there are only two possible graph structures, and we can work out the probability of finding one or the other, if the process of adding ties is purely random. There are also a couple of possible degree-distributions. If we observe the “3-line” structure, there is one node with a degree of 2, two with degree of 1, and all the rest have degree of zero. If we observe the two-dyad graph, there are four nodes with degree of 1, and all the rest have a degree of zero.
The numbers of basic structures in a graph (dyads, lines, triangles, etc.), and the shape of the degree distribution of the graph, change as the density of the graph increases.
As we add the third tie, there is a new range of possibilities for emergent structures. We could now have three dyads and remaining isolates, or we could have a line of 4 connected nodes and remaining isolates, or we could have a single closed triad and remaining isolates, etc. The range of structures that could emerge as we add ties grows exponentially with the increasing density. One way we can represent the possible graphs is as a “tree” (or first-order Markov process). Indeed, it is even possible to work out the probability of each particular kind of graph of a given density. Each of the possible graphs also has an associated degree distribution. In some graphs, there will be nodes with high degree and there will be considerable inequality in the degree distribution. In other possible graphs, the degree distribution will have few “stars” (actors with high degree), and a more equal distribution.
The important lesson from random graphs is that they display emergent structure (cliques, triads, lines, and unequal “social capital”) that can arise entirely by random and path-dependent processes that do not depend on the attributes of the actors. For any given level of density, there is a determinate probability distribution of structural properties of a graph based entirely on random processes.
Real social actors, we suspect, don’t build social networks by adding ties at random as just described. But, there are two very interesting and useful things about this “random graph” model.
First, to some degree at least, ties probably do form “at random” in social groups. So, when we see a network that displays “lines” and “dyads” and “closed triads” and “4-lines” we need to be careful to not over-interpret what is going on. In some graphs of a given density, it is possible to observe a single “leader” with very high degree – and most other nodes with very low degree – and this can happen by purely random processes. So, when we look at a real social network, it is very helpful to remember that there is some chance that what we are seeing is, in fact, the realization of a purely random statistical process, rather than non-random social organizing processes.
Second, the random graph model is also the simplest baseline model of how emergent structure may be a “cause” in itself. Sociologists have proposed a number of theories of how social networks form that depend on structure itself, rather than the attributes of individual actors. “Preferential attachment” (Barabási & Albert, 1999) suggests that actors who have more ties (perhaps for entirely random reasons) may be more attractive as network partners and hence garner new partners at a preferential rate as density increases. In directed graphs, we might find a tendency for “reciprocity” so that if a tie already exists from A to B, it may well be that the next tie is more likely to emerge from B to A than any other possibility. If A is already connected to B, and B is already connected to C, the “transitive” theory (Wasserman & Faust, 1994) suggests that an AC tie is more likely to develop next than any other random tie. To judge whether any of these kinds of structural processes are actually present in an observed network, we need to know whether the observed numbers of “stars,” “reciprocated ties,” or “transitive triads” (for example) differ from what would happen entirely by random processes.
The P1 model is a method of describing the structure of an observed network in terms of some of these basic structural processes. The unit of observation, or case, in P1 (and the other stochastic models of graphs) is the dyad. For a non-directed graph, each dyad can be of one of two types: null (no tie), or present (tie). For a directed graph, each dyad is one of three types: null (no tie), asymmetric (a tie from A to B, or from B to A, that is not reciprocated), or mutual (a reciprocated tie between A and B).
The P1 model hypothesizes that the probability a given dyad is null, asymmetric, or mutual is the realization of four structural processes. The fitted model assigns parametric values to these four processes. The first key parameter is theta ( θ ), which reflects the effect of total density on the probability that any given dyad is asymmetric or mutual, instead of null. The second key parameter is alpha ( α ), which reflects the out-degree or “expansiveness” of each node (there are as many alpha parameters as there are nodes). Alpha, then, fits the out-degree distribution of the graph, and reflects individual differences in the propensity to seek ties. The third key parameter is beta ( β ), which describes the “attractiveness,” or “popularity,” or “status” of nodes by modeling variation in the in-degree of nodes. Again, there are as many beta parameters as there are nodes. The fourth key parameter is rho ( ρ ) which reflects the tendency toward reciprocity (that is, given that a dyad contains one tie, what is the probability that it contains a second?). The P1 model does not directly address the question of closure or transitivity. These structural aspects were subsequently addressed with additional P and ERG models.
The parameters of the P1 model are estimated by fitting three simultaneous equations to the dyadic data (From Borgatti, et al. UCINET 6):
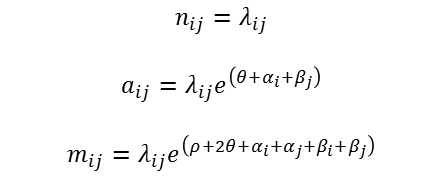
In the equations above, nij represents the probability that a given tie in a network will be null, aij represents the probability it will be asymmetric, and mij represents the probability it will be mutual. The model suggests that the probability a given dyad is null is equal to a constant, lambda. Lambda is simply a scalar to assure that the probabilities of the various types sum to 1.0. The probability that a dyad is asymmetric is a function of the overall graph density plus the expansiveness and attractiveness of the two nodes in the dyad. The likelihood that a dyad is mutual (reciprocated ties) is a function of overall density, the expansiveness of both actors, the attractiveness of both actors, and an additional graph-wide propensity (rho) for reciprocity. Note that the model is log-additive (or multiplicative). That is, the effects of the out-degree distribution, in-degree distribution, and reciprocity multiply modify the effects of density.
Figure 7.3 shows a portion of the results of running UCINET>Network>P1 on the asymmetric acquaintanceship ties in our social networks class at the end of the academic term (Wave 4).
Figure 7.3. UCINET’s P1 Analysis of Wave 4 (Asymmetric) Student Acquaintanceship
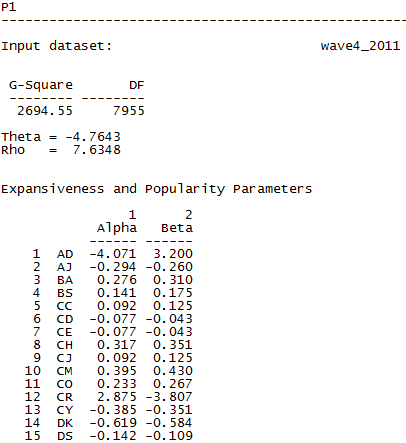
The first bit of information given in the output is the “badness of fit” (G-square) statistic and associated degrees of freedom. As UCINET’s documentation suggests, it is difficult to interpret this value precisely because the distributional assumptions are unknown. A rough comparison to the chi-square distribution with the same degrees of freedom suggests that the P1 model leaves significant residual variation (the residuals are available as output).
Next, the estimated parameters of the model are given. Theta (the density parameter) is -4.7643. The exponentiated value is 0.0085. Rho has a large positive value (7.6348), which suggests that if there is a single tie between two actors, the odds that there is a second (reciprocating) tie are over seven times as large as we would expect in a random graph of the same overall density, controlling for the out and in degrees of the members of the dyad. That is, there is a notable tendency toward reciprocation in acquaintanceship nominations which is hardly a surprising result.
Last, the parameter for the expansiveness and attractiveness of each actor are shown. We see, for example, that actor AD tends to initiate fewer ties than we would expect (alpha), but to receive more in-ties than we would expect in a random model (beta). Examining the distribution of these parameters allows us to see the shape of the in-degree distribution and the out-degree distribution. This describes the extent to which our graph displays unequal expansiveness and attractiveness, controlling for overall density and the observed tendency toward reciprocation.
UCINET’s implementation of P1 is a purely descriptive tool to identify actors who are in-stars, and out-stars, and to evaluate the magnitude of reciprocity (controlling for total density and the observed degree distributions). To test the statistical significance of the parameters, one must generate a large number of random graphs of the same density, fit the P1 model, and develop sampling distributions of the alpha, beta, and rho parameters. This computationally intensive process is characteristic of the methodology of all stochastic graph models, and is best pursued in software specifically designed for the purpose (e.g. ERGM, PNET, Siena).
The P1 model itself has largely been supplanted by more recent developments (see particularly Harris, 2014 for an excellent history), that allow more complex structural effects, hypothesis testing, and the inclusion of actor attributes and dyadic attributes. The P1 model, though, represents a major step forward in modeling (i.e. predicting and testing hypotheses about) network structures. Among the most important of the lessons of the P1 model are:
The idea of treating the dyad as the unit of analysis as a way of approaching the prediction of social structure.
The use of the Markov approach to understand how the probabilities of random graphs with different structures emerge with increases in density.
The recognition that the textures of social networks may be generated by structural processes, as well as the agency of actors (e.g. preferential attachment, reciprocity, and closure). And, that these structural processes form a hierarchy of multiplicative (not additive) effects.
In this chapter, we introduced many of the key concepts used in models of network selection. We discussed the ways that a network structure itself can become the dependent variable of predictive models. We also introduced network self-organization processes, actor attribute processes, and exogenous context as three mechanisms guiding the evolution of network structures.
Additionally, we outlined the importance of the triad census and how it can be computed in UCINet. We concluded the chapter with an introduction to the P1 model and a discussion of the importance of modeling random network processes.
Barabási, Albert-Laszlo and Reka Albert. 1999. “Emergence of Scaling in Random Networks,” Science, 286, 509-512.
Harris, Jenine K. 2014. An Introduction to Exponential Random Graph Modeling. Los Angeles: Sage Publications (Quantitative Applications in the Social Sciences series #173).
Holland, Paul W., and Samuel Leinhardt. 1981. "An Exponential Family of Probability Distributions for Directed Graphs." Journal of the American Statistical Association, 76(373):33-6.
Lusher, Dean and Garry Robins. 2013. “Formation of Social Network Structure.” Pp. 16-28 in Exponential Random Graph Models for Social Networks, edited by D. Lusher, J. Koskinen, and G. Robbins. Cambridge: Cambridge University Press.
Wasserman, Stanley, and Katherine Faust. 1994. Social Network Analysis: Methods and Applications. Cambridge: Cambridge University Press.